 大家在实际项目中对数据ID的生成肯定每次都会纠结?纠结一:如果用数据库的自增模式导致今后的分库分表无法分布式,如果要分布式,是不是考虑步长吧纠结二:如果用GUID/UUID方式虽然简单也可分布式,但可能在有些数据库中索引效率肯定没有数字类型的索引效率高纠结三:如果用redis的数字自增模式,考虑到肯定要自己做开发整合,还需考虑redis今后的吞吐承受能力,需要你额外的集群部署来增加吞吐量,那你还要掌握redis的运维知识
大家在实际项目中对数据ID的生成肯定每次都会纠结?纠结一:如果用数据库的自增模式导致今后的分库分表无法分布式,如果要分布式,是不是考虑步长吧纠结二:如果用GUID/UUID方式虽然简单也可分布式,但可能在有些数据库中索引效率肯定没有数字类型的索引效率高纠结三:如果用redis的数字自增模式,考虑到肯定要自己做开发整合,还需考虑redis今后的吞吐承受能力,需要你额外的集群部署来增加吞吐量,那你还要掌握redis的运维知识 大家在实际项目中对数据ID的生成肯定每次都会纠结?
纠结一:如果用数据库的自增模式导致今后的分库分表无法分布式,如果要分布式,是不是考虑步长吧
纠结二:如果用GUID/UUID方式虽然简单也可分布式,但可能在有些数据库中索引效率肯定没有数字类型的索引效率高
纠结三:如果用redis的数字自增模式,考虑到肯定要自己做开发整合,还需考虑redis今后的吞吐承受能力,需要你额外的集群部署来增加吞吐量,那你还要掌握redis的运维知识
纠正四:利用第三方框架生成唯一ID,比如ZK,或者大公司的专门的ID开源框架,这个是不是你要去熟悉学习的成本
说了这么多,那我们正式谈谈我对这块的解决方案,我经历过大大小小的项目,也每次讨论数据表里的业务ID怎么去生成,我目前最近经手的项目最简单的方式是用雪花算法,但原有的雪花算法会生成出比较长的一个数字ID,那我们就稍微改造一下呗。
改造点:其实就是把时间间隔差缩短,自然而然生成的ID位数就小了,直接贴代码给各位看看
1、把唯一时间戳调整一下
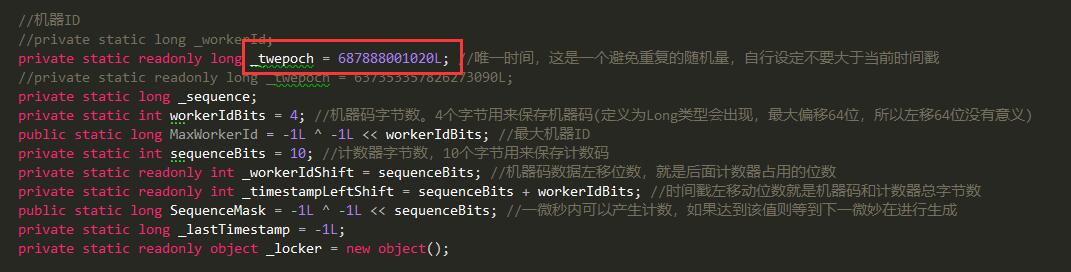
2、把当前的间隔时间戳调整一下
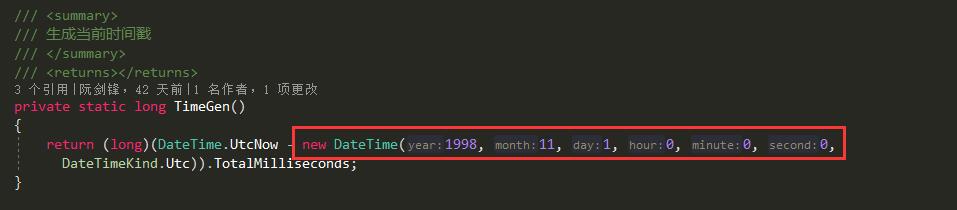
完工,这个生成的唯一ID数字相对已经比较短了,如果再把TimeGen的时间加大生成出来可能不是你们期望的,你们可以试试哦!
最终的生成ID效果图给各位看看
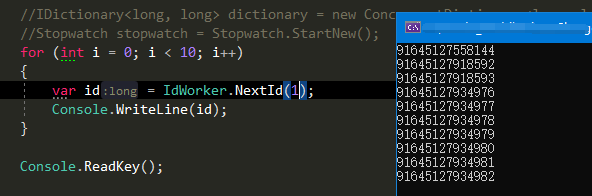
大家完全不用担心ID生成重复,只要控制好workId,就能生成唯一性
接下来说一下如何运用到项目中
大家可能觉得运用不就是很简单嘛,实际写到代码里调用可以了。但我说的是运用的意思是如何用好它,首先你的项目一开始没有考虑分布式机制,单纯的就是一个API或者服务能处理一套业务流程,那就比较简单的在项目里调用可以了;
如果准备考虑部署N多个同场景的业务处理服务,并且可能跨多服务器集群部署,那可以把ID生成独立做成微服务,并且也可以负载它,并且控制好workId,那就大功告成了。
建议:生成后的ID,完全可以当主键KEY,也可以当作业务单来运用实际的业务流程中(比如订单号、流水单号等,如果区分单据那还可以加上你的自定义前缀字母)
那就贴出调整后的雪花算法的代码,希望给大家有所帮助,如有什么问题,可评论留言,今后有什么好东西我也继续分享给各位,也请大家多多指教,互相学习。
1 public class IdWorker 2 { 3 //机器ID 4 //private static long _workerId; 5 private static readonly long _twepoch = 687888001020L; //唯一时间,这是一个避免重复的随机量,自行设定不要大于当前时间戳 6 //private static readonly long _twepoch = 637353357826273090L; 7 private static long _sequence; 8 private static int workerIdBits = 4; //机器码字节数。4个字节用来保存机器码(定义为Long类型会出现,最大偏移64位,所以左移64位没有意义) 9 public static long MaxWorkerId = -1L ^ -1L << workerIdBits; //最大机器ID10 private static int sequenceBits = 10; //计数器字节数,10个字节用来保存计数码11 private static readonly int _workerIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数12 private static readonly int _timestampLeftShift = sequenceBits + workerIdBits; //时间戳左移动位数就是机器码和计数器总字节数13 public static long SequenceMask = -1L ^ -1L << sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成14 private static long _lastTimestamp = -1L;15 private static readonly object _locker = new object();16 17 /// <summary>18 /// 机器码19 /// </summary>20 /// <param name="workerId"></param>21 public IdWorker(long workerId=1)22 {23 //if (workerId > MaxWorkerId || workerId < 0)24 //throw new Exception($"worker Id can't be greater than {workerId} or less than 0 ");25 //_workerId = workerId;26 }27 28 public static long NextId(long workerId)29 {30 lock (_locker)31 {32 long timestamp = TimeGen();33 if (_lastTimestamp == timestamp)34 { //同一微妙中生成ID35 _sequence = (_sequence + 1) & SequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限36 if (_sequence == 0)37 {38 //一微妙内产生的ID计数已达上限,等待下一微妙39 timestamp = TillNextMillis(_lastTimestamp);40 }41 }42 else43 { //不同微秒生成ID44 _sequence = 0; //计数清045 }46 if (timestamp < _lastTimestamp)47 { //如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过48 throw new Exception($"Clock moved backwards. Refusing to generate id for {_lastTimestamp - timestamp} milliseconds");49 }50 _lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳51 long nextId = (timestamp - _twepoch << _timestampLeftShift) | workerId << _workerIdShift | _sequence;52 return nextId;53 }54 }55 56 /// <summary>57 /// 获取下一微秒时间戳58 /// </summary>59 /// <param name="lastTimeStamp"></param>60 /// <returns></returns>61 private static long TillNextMillis(long lastTimeStamp)62 {63 long timestamp = TimeGen();64 while (timestamp <= lastTimeStamp)65 {66 timestamp = TimeGen();67 }68 return timestamp;69 }70 71 /// <summary>72 /// 生成当前时间戳73 /// </summary>74 /// <returns></returns>75 private static long TimeGen()76 {77 return (long)(DateTime.UtcNow - new DateTime(1998, 11, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;78 }79 }
最后来一局感慨:简单也是美!!!
原文转载:http://www.shaoqun.com/a/481879.html
isbn:https://www.ikjzd.com/w/174
名人堂是什么:https://www.ikjzd.com/w/1082
jpgoodbuy:https://www.ikjzd.com/w/1553
大家在实际项目中对数据ID的生成肯定每次都会纠结?纠结一:如果用数据库的自增模式导致今后的分库分表无法分布式,如果要分布式,是不是考虑步长吧纠结二:如果用GUID/UUID方式虽然简单也可分布式,但可能在有些数据库中索引效率肯定没有数字类型的索引效率高纠结三:如果用redis的数字自增模式,考虑到肯定要自己做开发整合,还需考虑redis今后的吞吐承受能力,需要你额外的集群部署来增加吞吐量,那你还要
heap:https://www.ikjzd.com/w/2012
zappos:https://www.ikjzd.com/w/330
【巴厘岛旅游费用需要多少】-去巴厘岛旅游要多少钱:http://tour.shaoqun.com/a/66380.html
假日大夫山森林公园几点关门?:http://tour.shaoqun.com/a/1818.html
菜鸟网:https://www.ikjzd.com/w/1547
No comments:
Post a Comment