项目背景
最近,做一个按优先级和时间先后排队的需求。用 Redis 的 sorted set 做排队队列。
主要使用的 Redis 命令有, zadd, zcount, zscore, zrange 等。
测试完毕后,发到线上,发现有大量接口请求返回超时熔断(超时时间为3s)。
Error日志打印的异常堆栈为:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.ConnectException: Connection timed out (Connection timed out)
Caused by: java.net.ConnectException: Connection timed out (Connection timed out)
且有一个怪异的现象,只有写库的逻辑报错,即 zadd 操作。像 zadd, zcount, zscore 这些操作全部能正常执行。
还有就是报错和正常执行交错持续。即假设每分钟有1000个 Redis 操作,其中900个正常,100个报错。而不是报错后,Redis 就不能正常使用了。
问题排查
1.连接池泄露?
从上面的现象基本可以排除连接池泄露的可能,如果连接未被释放,那么一旦开始报错,后面的 Redis 请求基本上都会失败。而不是有90%都可正常执行。
但 Jedis 客户端据说有高并发下连接池泄露的问题,所以为了排除一切可能,还是升级了 Jedis 版本,发布上线,发现没什么用。
2.硬件原因?
排查 Redis 客户端服务器性能指标,CPU利用率10%,内存利用率75%,磁盘利用率10%,网络I/O上行 1.12M/s,下行 2.07M/s。接口单实例QPS均值300左右,峰值600左右。
Redis 服务端连接总数徘徊在2000+,CPU利用率5.8%,内存使用率49%,QPS1500-2500。
硬件指标似乎也没什么问题。
3.Redis参数配置问题?
1 JedisPoolConfig config = new JedisPoolConfig(); 2 config.setMaxTotal (200); // 最大连接数 3 config.setMinIdle (5); // 最小空闲连接数 4 config.setMaxIdle (50); // 最大空闲连接数 5 config.setMaxWaitMillis (1000 * 1); // 最长等待时间 6 config.setTestOnReturn (false); 7 config.setTestOnBorrow (false); 8 config.setTestWhileIdle (true); 9 config.setTimeBetweenEvictionRunsMillis (30 * 1000);10 config.setNumTestsPerEvictionRun (50);
基本上大部分公司的配置包括网上博客提供的配置其实都和上面差不多,看不出有什么问题。
这里我尝试把最大连接数调整到500,发布到线上,并没什么卵用,报错数反而变多了。
4.连接数统计
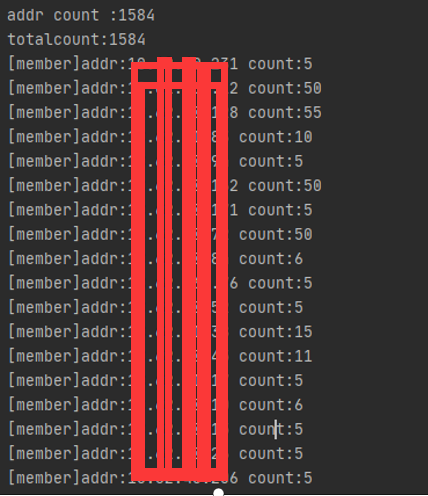
在 Redis Master 库上执行命令:client list。打印出当前所有连接到服务器的客户端IP,并过滤出当前服务的IP地址的连接。
发现均未达到最大连接数,确实排除了连接泄露的可能。
5.最大连接数调优和压测
既然连接远未打满,说明不需要设置那么大的连接数。而 Redis 服务端又是单线程读写。客户端创建过多连接,只会耗费资源,反而拖累性能。
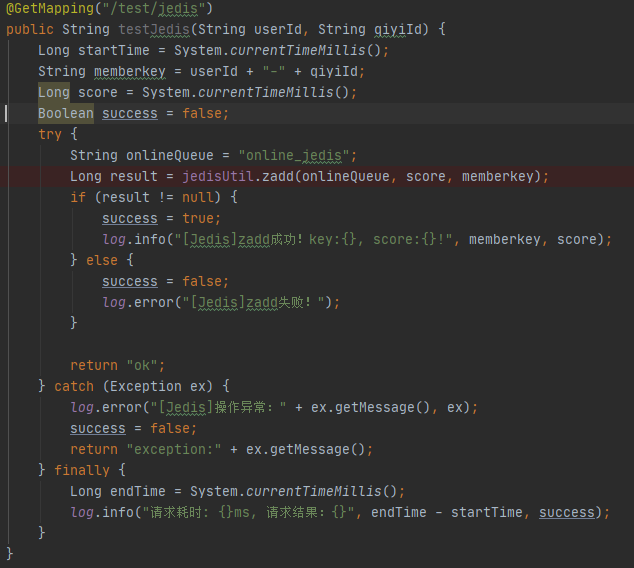
使用以上代码,在本机使用 JMeter 压测300个线程,连续请求30秒。
首先把最大连接数设为500,成功率:99.61%
请求成功:82004次,TP90耗时目测在50-80ms左右。
请求失败322次,全部为请求服务器超时:socket read timeout,耗时2s后,由 Jedis 自行熔断。
(这种情况造成数据不一致,实际上服务端已执行了命令,只是客户端读取返回结果超时)。


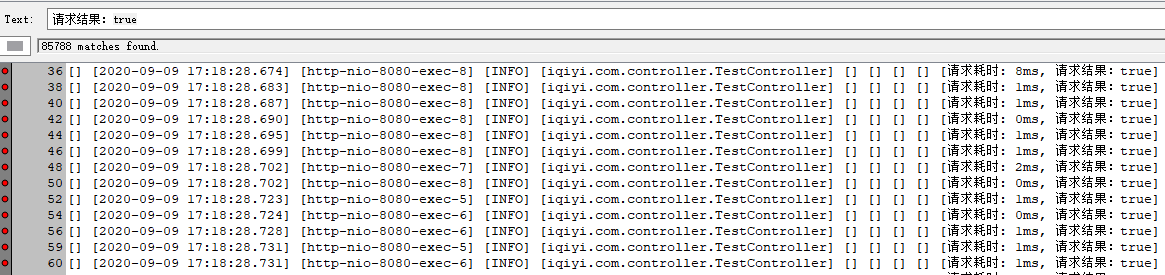
再把最大连接数设为20,成功率:98.62%(有一定几率100%成功)
请求成功:85788次,TP90耗时在10ms左右。
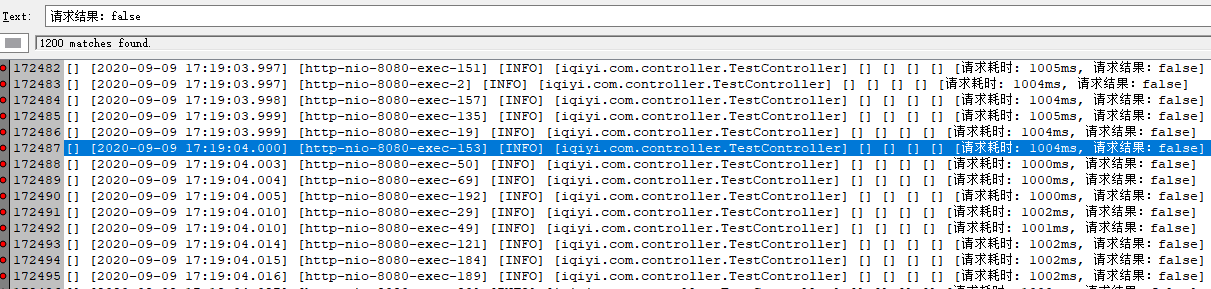
请求失败:1200次,全部为等待客户端连接超时:Caused by: java.util.NoSuchElementException: Timeout waiting for idle object,熔断时间为1秒。
再将最大连接数调整为50,成功率:100%
请求成功:85788次, TP90耗时10ms。
请求失败:0次。

综上,Redis 服务端单线程读写,连接数太多并没卵用,反而会消耗更多资源。最大连接数配置太小,不能满足并发需求,线程会因为拿不到空闲连接而超时退出。
在满足并发的前提下,maxTotal连接数越小越好。在300线程并发下,最大连接数设为50,可以稳定运行。
基于以上结论,尝试调整 Redis 参数配置并发布上线,但以上实验只执行了 zadd 命令,仍未解决一个问题:为什么只有写库报错?
果然,发布上线后,接口超时次数有所减少,响应时间有所提升,但仍有报错,没能解决此问题。
6.插曲 - Redis锁
在优化此服务的同时,把同事使用的另一个 Redis 客户端一起优化了,结果同事的接口过了一天开始大面积报错,接口响应时间达到8个小时。
排查发现,同事的接口仅使用 Redis 作为分布式锁。而这个 RedisLock 类是从其他服务拿过来直接用的,自旋时间设置过长,这个接口又是超高并发。
最大连接数设为50后,锁资源竞争激烈,直接导致大部分线程自旋把连接池耗尽了。于是又紧急把最大连接池恢复到200,问题得以解决。
由此可见,在分布式锁的场景下,配置不能完全参考读写 Redis 操作的配置。
7.排查服务端持久化
在把客户端研究了好几遍之后,发现并没有什么可以优化的了,于是开始怀疑是服务端的问题。
持久化是一直没研究过的问题。在查阅了网上的一些博客,发现持久化确实有可能阻塞读写IO的。
"1) 对于没有持久化的方式,读写都在数据量达到800万的时候,性能下降几倍,此时正好是达到内存10G,Redis开始换出到磁盘的时候。并且从那以后再也没办法重新振作起来,性能比Mongodb还要差很多。
2) 对于AOF持久化的方式,总体性能并不会比不带持久化方式差太多,都是在到了千万数据量,内存占满之后读的性能只有几百。
3) 对于Dump持久化方式,读写性能波动都比较大,可能在那段时候正在Dump也有关系,并且在达到了1400万数据量之后,读写性能贴底了。在Dump的时候,不会进行换出,而且所有修改的数据还是创建的新页,内存占用比平时高不少,超过了15GB。而且Dump还会压缩,占用了大量的CPU。也就是说,在那个时候内存、磁盘和CPU的压力都接近极限,性能不差才怪。" ---- 引用自lovecindywang 的博客园博客
"内存越大,触发持久化的操作阻塞主线程的时间越长
Redis是单线程的内存数据库,在redis需要执行耗时的操作时,会fork一个新进程来做,比如bgsave,bgrewriteaof。 Fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,这个复制是主线程来做的,会阻塞所有的读写操作,并且随着内存使用量越大耗时越长。例如:内存20G的redis,bgsave复制内存页表耗时约为750ms,redis主线程也会因为它阻塞750ms。" ---- 引用自CSDN博客
而我们的Redis实例总内存20G,内存使用了50%,keys数量达4000w。
主从集群,从库不做持久化,主库使用RDB持久化。rdb的save参数是默认值。(这也恰好能解释通为什么写库报错,读库正常)
且此 Redis 已使用了几年,里面可能存在大量的key已经不使用了,但未设置过期时间。
然而,像 Redis、MySQL 这种都是由数据中台负责,我们并无权查看服务端日志,这个事情也不好推动,中台会说客户端使用的有问题,建议调整参数。
所以最佳解决方案可能是,重新申请 Redis 实例,逐步把项目中使用的 Redis 迁移到新实例,并注意设置过期时间。迁移完成后,把老的 Redis 实例废弃回收。
小结
1)如果简单的在网上搜索,Could not get a resource from the pool , 基本都是些连接未释放的问题。
然而很多原因可能导致 Jedis 报这个错,这条信息并不是异常堆栈的最顶层。
2)Redis其实只适合作为缓存,而不是数据库或是存储。它的持久化方式适用于救救急啥的,不太适合当作一个普通功能来用。
3)还是建议任何数据都设置过期时间,哪怕设1年呢。不然老的项目可能已经都废弃了,残留在 Redis 里的 key,其他人也不敢删。
4)不要存放垃圾数据到 Redis 中,及时清理无用数据。业务下线了,就把相关数据清理掉。
原文转载:http://www.shaoqun.com/a/478815.html
贝恩资本:https://www.ikjzd.com/w/1336
启明星软件:https://www.ikjzd.com/w/1436
c88是什么:https://www.ikjzd.com/w/1017.html
项目背景 最近,做一个按优先级和时间先后排队的需求。用Redis的sortedset做排队队列。 主要使用的Redis命令有,zadd,zcount,zscore,zrange等。 测试完毕后,发到线上,发现有大量接口请求返回超时熔断(超时时间为3s)。 Error日志打印的异常堆栈为: redis.clients.jedis.exceptions.JedisConnectionEx
斑马物流:https://www.ikjzd.com/w/1316
shopyy:https://www.ikjzd.com/w/1661
让人"又爱又恨"的德国市场,清关有多麻烦?:https://www.ikjzd.com/home/107627
亚马逊员工受贿?员工受贿将使亚马逊中国地区重新洗牌!:https://www.ikjzd.com/home/6822
印尼新平台Jackmall正式招商啦!商家入驻流程一览:https://www.ikjzd.com/home/93948